Reference:
Li, X., Li, Y., Du, Z., Li, F., Lu, K., & Li, J. (2024). Split to Merge: Unifying separated modalities for unsupervised domain adaptation. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2403.06946
Article:
- Global issue
- Unsupervised Domain Adaptation (UDA)를 수행하는 데 있어서 이미지와 텍스트의 정보를 효과적으로 통합하는 것이 중요: In image classification, aligning vision features while neglecting semantic content can lead to difficulties in differentiating complex samples
- Large vision-language models (VLMs) like CLIP have demonstrated good zero-shot learning performance in the unsupervised domain adaptation task through joint multimodal pretraining on images and texts
- zero-shot learning (제로샷 학습): 모델이 학습되지 않은 새로운 class나 domain에 대해 예측을 수행할수 있도록 하는 학습 방식
- ex) 고양이와 개의 이미지만 학습한 모델이, 학습되지 않은 호랑이 이미지를 보고 호랑이라고 예측할 수 있는 능력
- zero-shot learning (제로샷 학습): 모델이 학습되지 않은 새로운 class나 domain에 대해 예측을 수행할수 있도록 하는 학습 방식
- Large vision-language models (VLMs) like CLIP have demonstrated good zero-shot learning performance in the unsupervised domain adaptation task through joint multimodal pretraining on images and texts
- Unsupervised Domain Adaptation (UDA)를 수행하는 데 있어서 이미지와 텍스트의 정보를 효과적으로 통합하는 것이 중요: In image classification, aligning vision features while neglecting semantic content can lead to difficulties in differentiating complex samples
Unsupervised Domain Adaptation
비지도 도메인 적응(Unsupervised Domain Adaptation, UDA)은 모델이 학습된 도메인(출발 도메인)에서 다른 도메인(목표 도메인)으로 일반화할 수 있도록 하는 방법
목표 도메인에는 라벨이 없는 데이터만 존재하며, 출발 도메인의 라벨이 있는 데이터를 활용하여 목표 도메인에서의 성능을 개선하며 데이터 부족 문제를 해결함.
1. 출발 도메인에서 모델 학습
출발 도메인 (Source Domain): 라벨이 있는 데이터가 있는 도메인, 여기서 모델이 처음 학습 됨.
2. 특징 추출 및 도메인 적응:
출발 도메인과 목표 도메인의 특징을 추출하고, 두 도메인의 분포 차이를 줄이기 위해 적응함.
자주 사용되는 방법 중 하나는 도메인 적대적 신경망 (Domain-Adversarial Neural Network, DANN)
이 방법은 도메인 분류기를 사용하여 출발 도메인과 목표 도메인을 구분하고, 모델이 두 도메인을 구분하지
못하도록 학습.
목표 도메인 (Target Domain): 라벨이 없는 데이터가 있는 도메인, 모델이 일반화되어야 하는 도메인
3. 목표 도메인에서의 성능 평가
적응된 모델을 사용하여 목표 도메인에서 예측을 수행하고 성능을 평가.
- Focused issue
- Modality gap: 비전-언어 모델(VLM)에서 시각적 특징(이미지)과 텍스트 특징(언어)이 잘 통합되지 않고 각각 독립적으로 존재하는 문제
- 이는 텍스트와 시각적 구성 요소가 서로 맞지 않는 고유한 단서를 포함하고 있기 때문.
- 최근 연구에 따르면, VLM(비전-언어 모델)들은 시각적 특징과 텍스트 특징을 정확히 일치시키지 못하는 문제가 있음. 학습 노력에도 불구하고, 시각적 특징과 텍스트 특징은 종종 별도로 분포되어 있음.
- 이는 텍스트와 시각적 구성 요소가 서로 맞지 않는 고유한 단서를 포함하고 있기 때문.
- 대부분의 Transfer Learning 접근 방식은 언어 또는 시각적 요소 중 하나에만 초점을 맞추며, 두 모달리티 간의 세밀한 상호 작용을 간과
- Modality 간의 특정 모달리티에 의존하지 않는 (공통된) 정보 교환 문제
- 두 모달리티 간의 세밀한 특성을 유지하면서 공통되는 정보를 교환하는 것이 어려움.
- Modality gap: 비전-언어 모델(VLM)에서 시각적 특징(이미지)과 텍스트 특징(언어)이 잘 통합되지 않고 각각 독립적으로 존재하는 문제
- Method: Unified Modality Separation (UniMoS)
- 모달리티를 정확히 분리한 후, 두 모달리티 간의 공통되는 특징을 교환
- Modality-Ensemble Training (MET) method fosters the exchange of modality-agnostic information while maintaining modality-specific nuances.
- Modality-agnostic information: 특정 모달리티에 의존하지 않는다는 의미. 예를 들면, 텍스트와 이미지 둘 다에 공통적으로 적용될 수 있는 정보
- Mechanism: 각 예측값은 모달리티 별로 학습된 특징을 기반으로 생성되며, 가중치 생성기를 통해 최종적으로 결합되어 더 정확하고 일관된 예측을 제공
- Input Processing: Encoders from pre-trained CLIP
- Text Encoder: Processing the textual inputs (feature mu_i)
- Vision Encoder: Processing the visual inputs (feature f_v)
- Modality Separation Networks
- Text Separator: Divides the vision encoder's output (f_v) into language-associated component (LAC)
- f_lac: 언어적 특징
- Vision Separator: Divides the vision encoder's output (f_v) into vision-associated component (VAC)
- f_vac: 시각적 특징
- Text Separator: Divides the vision encoder's output (f_v) into language-associated component (LAC)
- Zero-shot Knowledge Distillation
- Teacher Knowledge from CLIP: Zero-shot results from the pre-trained CLIP model (teacher model) are used to guide the LAC
- helps in maintaining the semantic richness of the LAC
- CLIP 모델의 text feature mu_i와 LAC f_lac 간의 cosine 유사도를 계산하여 logit l_i를 형성
- Teacher Knowledge from CLIP: Zero-shot results from the pre-trained CLIP model (teacher model) are used to guide the LAC
- Orthogonal Regularization and Alignment
- Ensures that the LAC and VAC are distinct and do not overlap, preserving their modality-specific characteristics
- Modality Discriminator: Source and Target domain 간에 LAC와 VAC 일치시킴
- Source Domain에서 학습된 특징(LAC 및 VAC)이 Target Domain에서도 잘 작동하도록 함.
- Linear Classifier
- Linear Classifier: VAC는 linear classifier을 통해 최종 예측 y_hat_va를 형성
- Weight Generator: Modality-Ensemble Training (MET)
- Modality outputs (LAC 및 VAC)을 결합하여 VAC 학습 시킴
- 각 모달리티의 중요도 조정
- Integrates the outputs from both modalities to leverage modality-specific information while preserving shared context
- Final output: A combination of the VAC and LAC outputs weighted by dynamically learned weights
- Modality outputs (LAC 및 VAC)을 결합하여 VAC 학습 시킴
- Input Processing: Encoders from pre-trained CLIP

| : Language-Associated Component (LAC)의 예측값 텍스트와 관련된 특징을 기반으로 예측값을 생성하여 언어적 정보와의 일관성을 유지 |
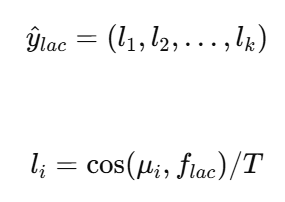 T는 CLIP에서 사전 학습된 매개변수 |
| : Vision-Associated Component (VAC)의 예측값 시각적 특징을 기반으로 예측값을 생성하여 이미지 정보를 반영 |
 |
|
|
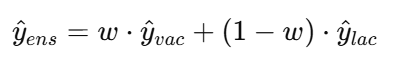 Weight Generator은 w를 학습하여 LAC와 VAC 출력 결합 |
Zero-shot Knowledge Distillation
사전 학습된 모델(Teacher 모델)에서 얻은 지식을, 학습되지 않은 새로운 데이터나 작업(zero-shot)에서 예측 성능을 향상시키기 위해 다른 모델(student 모델)에 전달하는 기술
Knowleddge Distillation: 대규모 모델(teacher)에서 소규모 모델(student)로 지식을 전이하는 방법
지식 전이 과정:
1. Teacher Knowledge Extraction: 사전 학습된 teacher 모델에서 지식을 추출합니다.
2. Knowledge Distillation: 추출된 지식을 student 모델에 전달합니다.
Summary
- Unsupervised Domain Adaptation (UDA)를 수행하는 데 있어서 이미지와 텍스트의 정보를 효과적으로 통합하는 것이 중요 => CLIP 모델은 이러한 통합의 좋은 예시이지만, 몇 가지 문제가 존재 => 이를 해결하기 위해 이 논문에서는 UniMoS(Unified Modality Separation)를 제안
Overall Reflection
여태 읽은 논문 중에 난이도가 제일 높았던 것 같다. 멀티 모달에 대한 관계성에 눈에 띄기 시작했고, 멀티모달로 훈련할 때 각자 가지고 있는 고유의 정보를 효율적으로 학습함과 동시에, 이 두 모달리티의 관계로 인해 얻을 수 있는 정보들도 학습해야한다는 중요성을 깨닫게 되었다.