Reference:
Han, W., Kim, C., Ju, D., Shim, Y., & Hwang, S. J. (2024). Advancing Text-Driven Chest X-Ray Generation with Policy-Based Reinforcement Learning. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2403.06516
Article:
- Global issue
- Recent advances in text-conditioned image generation diffusion models for generating Chest X-rays (CXRs) from diagnostic reports (Report-to-CXR generation)
- Addresses medical field challenges, such as data scarcity and privacy concerns (i.e., privacy-free medical image data for medical education or research)
- Recent advances in text-conditioned image generation diffusion models for generating Chest X-rays (CXRs) from diagnostic reports (Report-to-CXR generation)
Diffusion Model
Data Generative Model의 일종으로, 주로 이미지 생성에 사용됨.
이 모델은 데이터 분포를 학습하여, 랜덤한 noise로부터 점진적으로 데이터를 생성함.
데이터를 점진적으로 noise로 변환하고, 이 과정을 반대로 실행하여 noise에서 데이터를 복원함.

Text-conditioned Image Generation Diffusion Model
주어진 텍스트 설명을 기반으로 이미지를 생성하는 모델
이 모델은 diffusion process를 통해 점진적으로 이미지를 생성하며, text condition을 활용하여 생성된 이미지가 주어진 텍스트 설명과 일치하도록 유도함.
- Focused issue
- 기존 Diffusion Models은 의료 이미지의 복잡한 특성과 미세한 진단적 차이를 정확히 표현하지 못함.
- such as minor tissue texture varations per patient or disease
- 기존 Diffusion Models은 Training data의 log-likelihood를 maximization하는 것을 목표로 함. 이는 모델이 주로 training dataset의 분포와 일치하는 이미지를 생성하도록하여 의료 이미지에서의 중요한 미세한 변화를 반영하지 못하게 되는 것처럼 낮은 일반화 능력을 야기할 수 있음.
- Solution: Training diffusion denoising as a multi-step decision making problem
- 기존 Diffusion Models은 의료 이미지의 복잡한 특성과 미세한 진단적 차이를 정확히 표현하지 못함.
- Contribution of this article:
- Introduce CXRL, jointly fine-tuning the image generator and learnable adaptive condition embeddings (ACE) to condition the image generation process flexibly
- Applying RL to text-conditioned medical image synthesis (CXRs)
- Advancing report-to-CXR generation with a RLCF-based rewarding mechanism
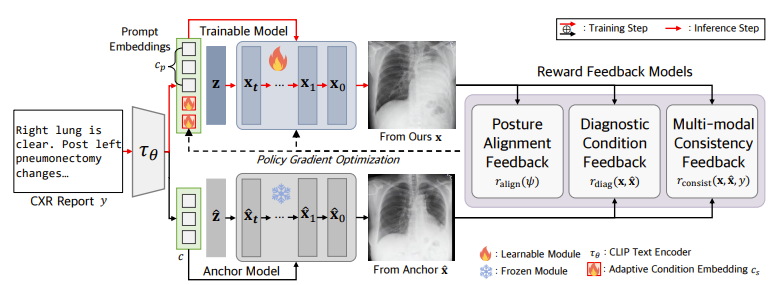
- Methods: CXRL
- motivated by the potential of reinforcement learning (RL)
- integrate a policy gradient RL approach with well-designed multiple distinctive CXR-domain specific reward models to enhance the denoising process
- CXRL framework includes:
- Optimizing learnable adaptive condition embeddings (ACE)
- ACE: Text 설명을 벡터로 변환하여, 모델이 이러한 조건을 기반으로 이미지를 생성할 수 있도록 도움. 습 과정을 통해 최적의 embedding을 학습할 수 있음.
- Image Generator, enabling the model to produce more accurate and higher perceptual CXR quality
- RL with Comparative Feedback (RLCF)
- a human like comparative evaluation that is more effective and reliable in complex scenarios compared to direct evaluation
- Optimizing learnable adaptive condition embeddings (ACE)
- Mechanism of CXRL: 무작위 Noise Vector을 사용하여 이미지를 생성하고, 피드백 과정을 통해 Reinforcement Learning을 사용하여 Parameter를 세부적으로 조정하면서 점진적으로 더 나은 이미지를 생성함.
- Embeddings
- Prompt Embeddings: Text Report를 Embedding vectors로 변환
- Learnable Adaptive Condition Embeddings (ACEs): 학습 가능하여 flexible한 입력 조건을 제공
- Report의 다양성으로 인해, 단순히 보고서 자체에만 의존하여 이미지를 생성하는 것은 한계가 있기에 ACE 도입
- Models (Image Generator)
- Trainable Model: Noise vector 'z'와 Embedding vectors를 입력으로 받아 CXR 이미지 생성 (a series of denoising steps을 통해)
- Anchor Model: 비교를 위한 기준 모델. 이 모델은 학습되지 않으며, 비교 피드백을 제공하는 데 사용됨.
- Reward Feedback Models
- Posture Alignment Feedback: 생성된 CXR 이미지의 자세 정렬을 평가하는 피드백. CXR 이미지가 올바른 자세를 유지하도록 유도.
- Diagnostic Condition Feedback: 생성된 CXR 이미지의 진단적 조건을 평가하는 피드백. A state-of-the-art pretrained CXR lesion classifier를 사용하여 진단적 정확성을 평가.
- Multi-modal consistency Feedback: 생성된 CXR 이미지와 Text Report 간의 일관성(disagreement)을 평가하는 피드백. Large-scale Representations trained on CXR-report pairs을 사용하여 CXR 이미지와 보고서 간의 의미적 일치도를 평가.
- Policy Gradient Optimization
- Reward Feedback을 사용하여 Trainable Model을 Optimization
- Embeddings
- motivated by the potential of reinforcement learning (RL)
Reinforcement Learning (강화 학습)
Agent가 Environment와 상호작용하면서, 주어진 목표를 달성하기 위해 최적의 Action을 학습하는 Machine Learning의 한 분야
Agent는 State를 관찰하고, Action을 선택하며, 그 Action의 결과로 Reward을 받는다.
목표는 Reward를 최대화하는 Policy를 학습하는 것이다. 여기서 Policy는 주어진 상태에서 어떤 행동을 취할지를 결정하는 전략을 지칭한다. (보통 π(s)로 표기)
* 강화 학습의 흐름
1. Agent는 현재 State를 관찰합니다.
2. Policy에 따라 Action을 선택합니다.
3. 선택된 Action이 Environment에 영향을 미쳐 새로운 State로 전환되고 Reward을 받습니다.
4. Agent는 이 정보를 바탕으로 Policy을 업데이트하여 Reward을 최대화하는 방향으로 학습합니다.
Policy Gradient
Machine Learning에서 Agent가 직접적으로 Policy를 최적화하기 위해 사용하는 방법 중 하나
Agent가 Reward를 최대화하는 방향으로 Policy의 Parameter를 조절한다.
Overall Reflection:
Deep Learning에서 Gradient Descent Optimization으로 모델의 Parameter을 비교하는 건 알고 있었는데, Reinforcement Learning (Machine Learning 분야 중 하나)의 Policy Gradient Optimization은 처음 알게 됐음. Deep Learning 안에서만 놀 것이 아니라, Machine Learning의 다른 분야와의 융합도 생각했다는게 이 article의 key action인 것 같음.
'Reading Articles > Multimodal' 카테고리의 다른 글
| [논문리딩] Split to Merge: Unifying Separated Modalities for Unsupervised Domain Adaptation (0) | 2024.07.14 |
|---|---|
| [논문 리딩] VCodeR: Versatile Vision Encoders for Multimodal Large Language Models (0) | 2024.07.05 |